LLM Search for E-commerce: How Large Language Models Are Rewriting Retrieval
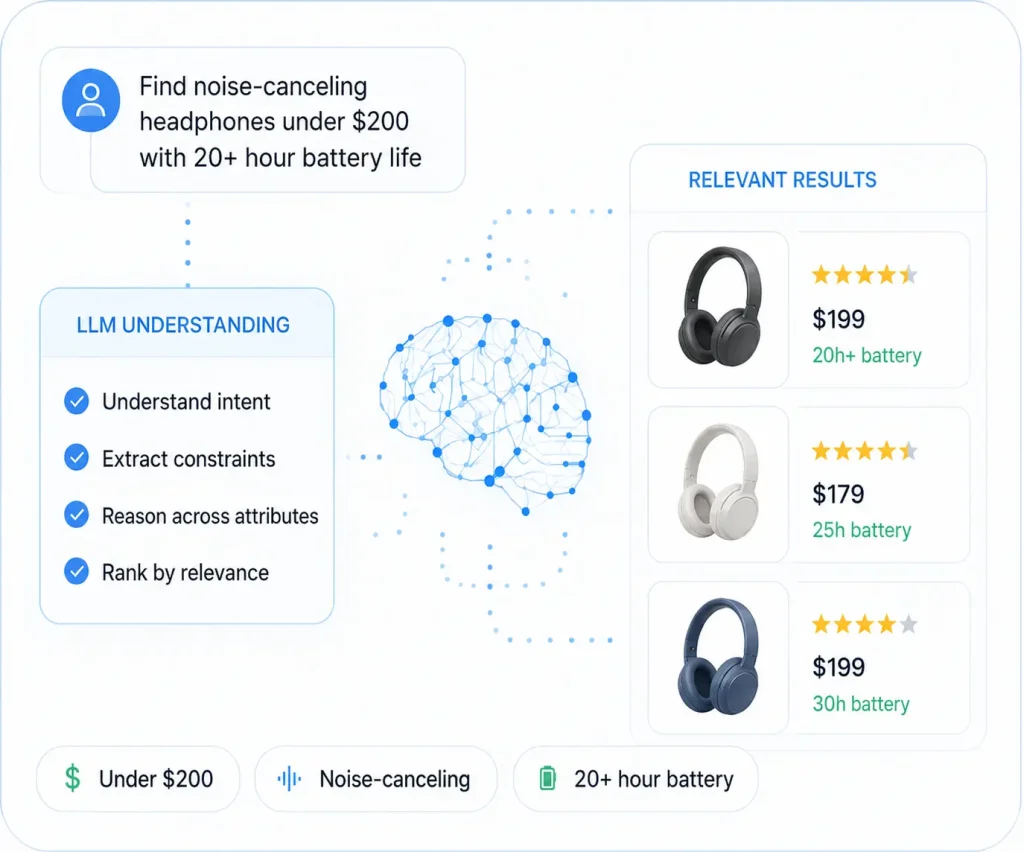
What LLM search adds that vector search alone can't
Multi-constraint queries
"Running shoes for flat feet under $150 that ship by Friday" requires parsing four orthogonal constraints (use case, condition, price, shipping). Vector search blends them into one similarity score; LLMs can extract and apply them as separate filters.
Reasoning queries
"I'm 5'4" and tend to overheat — what running gear should I get?" requires inference about size and breathability that no embedding captures directly.
Conversational refinement
"Show me the cheaper one in blue" only makes sense if the engine remembers what was just shown. LLMs maintain conversation state.
Explanation and justification
"Why did you recommend this?" — vector search returns ranked results with no narrative; LLMs can explain.
The RAG architecture: how LLM search actually works
Step 1 — Retrieval:
Vector search retrieves the top 50–200 candidate products for the query.
Step 2 — Context construction:
The candidate products are formatted into a structured prompt context.
Step 3 — LLM reasoning:
The LLM ranks, filters, or reasons about the candidates given the original query and any conversation context.
Step 4 — Response generation:
The LLM produces ranked results, optionally with explanations or comparison summaries.
The cost reality of LLM search at scale
Model
Approx. cost / 1K queries
Latency

The cost optimization patterns that actually work
Security, Compliance, and Enterprise-Grade Reliability
Hybrid retrieval depth
Does the platform combine vector + keyword + behavioral signals, or just stack an LLM on basic retrieval?
Grounding guarantees
What guardrails prevent hallucination? Are recommended products validated against the catalog?
Merchandising integration
Can growth teams pin, boost, and bury products without engineering tickets?
Conversational state management
Does the system handle multi-turn sessions, or only single-query?
Cost transparency
Per-query LLM costs should be visible in the dashboard, not buried in invoices.
Latency budgets
What's the p95 latency? Sub-500ms total is the modern bar.
Catalog sync freshness
Real-time updates or batch nightly?
Multi-language support
Native multilingual or per-language deployment?
Conversational search: the killer use case
Shopper:
System:
Shopper:
System:
Shopper:
System:
Shopper:
System:
Implementation paths: build, partner, or buy
Build path
Stack: Vector database (Qdrant, Weaviate, pgvector) + embedding pipeline + LLM gateway (vLLM or LiteLLM) + retrieval orchestration + reranking + frontend. Realistic timeline: 4–9 months with a 2–4 person team. Best for stores with engineering capacity and very specific requirements.
01
02
Partner path
Use individual building blocks (OpenAI embeddings, Pinecone, an LLM gateway) and stitch them together. Faster than full build, more flexible than full SaaS, but you still own the integration and ops.
Buy path
AI-native platforms like bCloud AI ship LLM search as a managed capability — vector retrieval, RAG orchestration, hallucination guardrails, and visual merchandising all included. Time-to-live is typically under two weeks. Cost is predictable. Best for most mid-market stores.
03
Grounding and hallucination: the trust problem
Strict grounding
The LLM is instructed (and prompt-engineered) to recommend only products from the retrieved candidate set. Never invent.
Structured output validation.
The model returns product IDs, which are then validated against the catalog before display. Any unknown ID is dropped.
No price or inventory generation
Prices and inventory come from the catalog data, never from the LLM. The LLM ranks; the catalog displays.
Refusal patterns
When the candidate set genuinely doesn't contain a match, the model is instructed to say so rather than fabricate.
Tactical tip
In any LLM search architecture, treat the model as a reranker and reasoner, not as a source of truth. Catalog data flows from your database, never from the model's parameters.
What LLM search for e-commerce delivers in real deployments
Metric
Vector search baseline
+ LLM layer
Why does this matter?
Multimodal LLM search
Image + text queries handled in the same model — "find shoes that look like this and cost under $80" with an image upload.
Personalized prompts
Per-shopper context (purchase history, browsing patterns) injected into the LLM prompt for personalized reasoning.
Agentic checkout
The search experience expands into a shopping agent that can compare, recommend, and even initiate checkout — not just retrieve.
Smaller, cheaper, better
Distilled and fine-tuned models continue closing the gap with frontier models at 10–50× lower cost.
Related posts
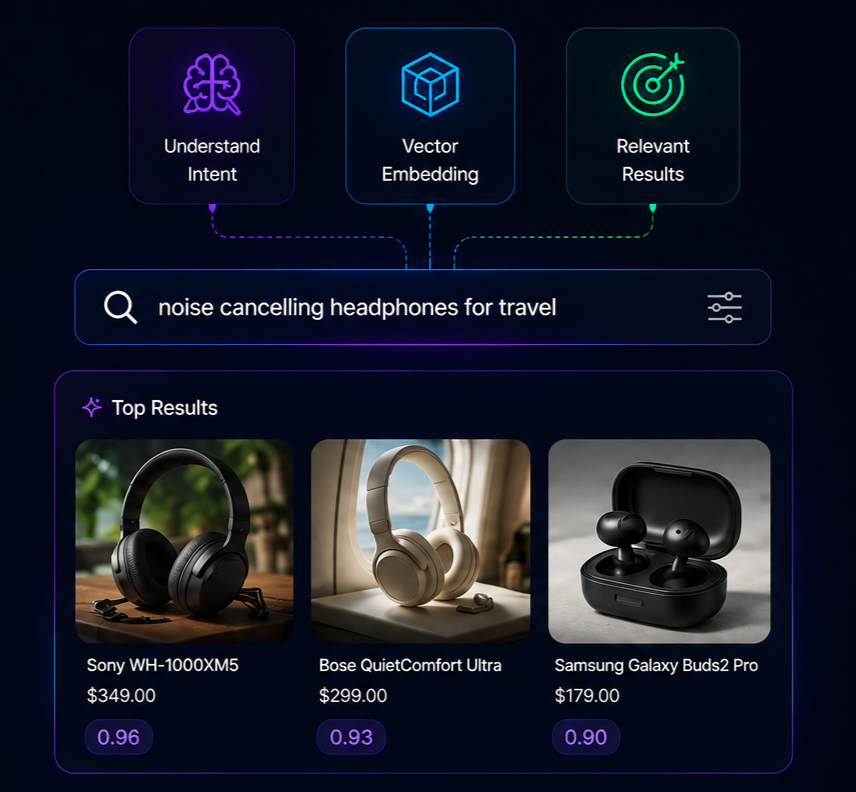
Vector Search Ecommerce
Vector search in ecommerce is a retrieval method that converts shopper queries and product catalogs into high-dimensional numerical vectors.

Semantic Search Product Catalog
Semantic search applied to a product catalog is a retrieval system that understands shopper intent rather than matching keywords.

AI Product Search
AI product search understands shopper intent instead of relying on exact keywords — helping ecommerce brands recover lost traffic, improve relevance.

AI E-Commerce Search Guide
Semantic search can find results that don’t use your exact terminology but address your actual need.

Trust Center
Comparing OpenSearch and bCloud AI as your e-commerce search engine? See the head-to-head on AI capability, deployment, pricing, and merchandising.
Semantic Search: Understanding Meaning, Not Just Keywords
Semantic search can find results that don’t use your exact terminology but address your actual need.
Zero Results Ecommerce
An AI search engine represents one of the most transformative technologies available to modern organizations.
AI Search
Discover how e-commerce AI search is revolutionizing product discovery, conversion rates, and customer experience.
Search Engine for an E-Commerce Website
AI-feature depth, total cost of ownership, and the flexibility your growth team has to merchandise without filing engineering tickets.
Enterprise AI News & Trends 2026
For enterprise leaders trying to understand what’s actually relevant to their organization.
Frequently asked questions
What is LLM search for e-commerce?
Does LLM search replace vector search?
How much does LLM search cost?
What about hallucination risk?
Can I run LLM search alongside my existing search?