
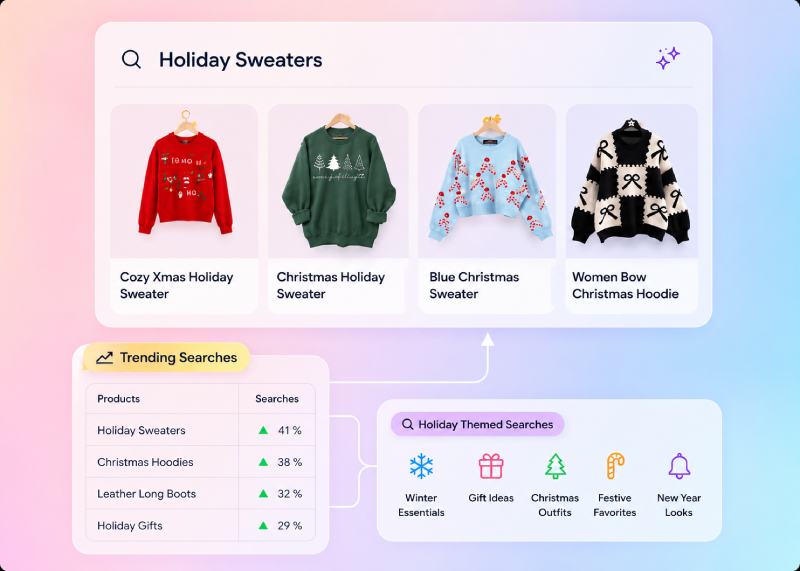
Vector Search Ecommerce:
The Complete 2026 Technical Guide
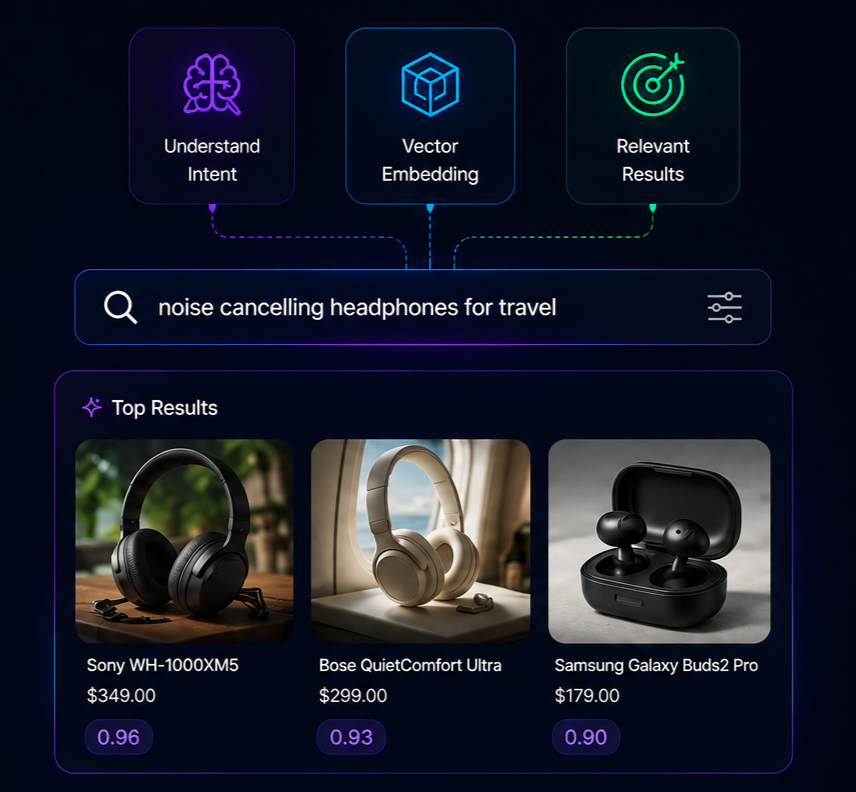
What is vector search and why does ecommerce need it?
The shopper behavior that made vector search inevitable
Long-tail descriptive queries
20–40% of e-commerce search queries are unique. Shoppers describe outcomes instead of exact product titles.
Voice and conversational input
Voice assistants and mobile search create longer natural-language queries. Traditional keyword systems struggle to understand these requests.
Multi-attribute intent
Searches combine recipient, price, category, intent, and constraints together. Keyword engines often treat these important attributes as noise.
How vector search ecommerce architectures actually work
The retrieval pipeline
At query time, the pipeline runs three steps: embed the query, retrieve the top-K nearest product vectors (typically K=100 or K=200), then rerank using business rules and behavioral signals. The reranking step is where commercial logic — boost in-stock items, surface high-margin SKUs, demote slow movers — gets applied without polluting the semantic similarity scores.
Aggressive facet filtering
Shoppers stack filters (size + color + price + brand) and the result set collapses to zero. Smart faceting suggests the closest matches instead.
Index
Type
Best for
The embedding model
An embedding model is a neural network that takes text in and produces a fixed-length numerical vector out. Popular open-source choices include all-MiniLM-L6-v2 (384 dimensions, fast) and BAAI/bge-large-en (1,024 dimensions, more accurate). OpenAI's text-embedding-3-small and Cohere's embed-v3 are common API options. Every product in your catalog is run through this model once, and the resulting vector is stored. Every shopper query is embedded the same way at query time.
Hybrid retrieval: why pure vector search isn't enough
BM25
Handles semantic intent, synonyms, descriptive queries, and conceptual matching to help shoppers find exactly what they mean, even when their search terms don't match product titles or keywords. Understands context, user intent, and natural language patterns to deliver more accurate and relevant search results.
01
02
Vector Similarity
Handles semantic intent, synonyms, descriptive queries, and conceptual matching to deliver highly relevant search results that go far beyond traditional keyword-based search. The AI understands the meaning behind customer queries, recognizes related terms and product relationships, and interprets natural language searches in context.
Real-world performance: what vector search actually delivers
Metric
Typical lift
Why
Operational considerations for vector search at scale
Latency budgets
Modern shoppers expect search results in under 300ms. The biggest contributors to latency are query embedding (typically 30–80ms) and index lookup (5–20ms with HNSW). Edge-cached responses across a global CDN bring p95 latency under 200ms.
Index freshness
Catalogs change. New products launch, prices update, inventory shifts. A robust vector index supports incremental updates — adding, updating, or removing items without rebuilding the entire index. Look for platforms that offer real-time sync rather than nightly rebuilds.
Embedding drift
Embedding models improve over time. When you upgrade from a 384-dimension model to a 1,024-dimension model, the entire catalog must be re-embedded. Plan for this in your architecture by versioning embeddings and supporting hot-swappable index migrations.
How To Fix Zero Results Ecommerce — fast
Roll your own
Pros
- Maximum control over every layer
- No per-query fees at scale
Cons
- 1–3 engineers for 3–6 months to ship
- Ongoing ops: model upgrades, sharding, monitoring
- A/B infra and merch tools all custom-built
Hosted SaaS
Pros
- Faster to ship than building
- Mature analytics and dashboards
Cons
- Per-request billing scales painfully
- Semantic features gated behind enterprise tier
- Vendor lock-in risk
AI-native platforms
Pros
- Ships in under a week
- Semantic + hybrid retrieval + reranking included by default
- Predictable pricing, no AI feature paywall
- Merchandising tools built in
Cons
- Newer to market, smaller ecosystems
How to pick the best e-commerce search for your store
Capability
Keyword search
Vector search
Common implementation pitfalls
The future of vector search ecommerce
Multimodal embeddings
Models like CLIP let shoppers search by image as easily as by text — "find shoes that look like this" works against the same vector index.
Reasoning-augmented retrieval
LLMs sit on top of vector retrieval to handle complex multi-step queries: "I need a gift for my dad who plays golf, costs around $80, and ships before Friday."
Personalized embeddings
Per-shopper embedding adjustments (based on browsing history) are starting to appear in production, customizing the semantic neighborhood for each visitor.
Frequently asked questions
What is vector search in ecommerce?
Is vector search better than Elasticsearch?
How much does vector search ecommerce cost?
Do I need to embed my entire catalog?
Related posts
Natural Language Product Search
Natural Language Product Search lets shoppers describe what they want in conversational language and returns relevant products even when no item is literally tagged with those phrases.

Semantic Search Product Catalog
Semantic search applied to a product catalog is a retrieval system that understands shopper intent rather than matching keywords.

AI Product Search
AI product search understands shopper intent instead of relying on exact keywords — helping ecommerce brands recover lost traffic, improve relevance.
AI Search Engine: Complete Implementation Guide
An AI search engine represents one of the most transformative technologies available to modern organizations.
Semantic Search: Understanding Meaning, Not Just Keywords
Semantic search can find results that don’t use your exact terminology but address your actual need.

Switch from hawksearch
Hawksearch is built on keyword matching and manual rules—technology from 2015.
AI Search
Discover how e-commerce AI search is revolutionizing product discovery, conversion rates, and customer experience.
Integrations
Eliminate silos. Automate workflows. Connect Shopify, Salesforce, Adobe Commerce and more — all in one cloud-native platform built for modern commerce.

AI Search BigCommerce
Comparing OpenSearch and bCloud AI as your e-commerce search engine? See the head-to-head on AI capability, deployment, pricing, and merchandising.
E-Commerce Search Engine
E-commerce search engine makes all the difference between a sale and an abandoned cart.

AI Vector Search That Understands Every Shopper
Improve search relevance, increase conversions, and reduce zero-result searches with advanced vector embeddings designed for modern e-commerce experiences.